
这是一个创建于 1871 天前的主题,其中的信息可能已经有所发展或是发生改变。
环境:
- 语言:php7.4
- 框架:hyperf 2.0
服务器
- nginx 1 台
- php api 4 台
- redis 1 台
- mysql 1 台
问题描述
- 目前项目在 qps 较高时遇到了响应时间延长的问题,新增了一台 api 服务器,并没有多大改善(原本是 3 台)
- 大概看了一下高并发时服务器的负载,并没有达到上限
- 平时 qps 可以支撑 1000 左右(3 台服务器),响应延迟保持在 450ms 左右。这两天请求增多 qps 达到 1300 左右,每个小时有十几分钟响应延迟会增加(多的时候响应会达到 3 、4 秒)(下面会附图),前 2 条大概排除了服务器的问题,现在考虑代码问题。下面附图把代码流程加了 time debug,并附带上比较耗时的代码段,麻烦各位大佬帮忙看看代码有没有性能瓶颈问题。
ps: 之前有段时间也遇到响应延迟问题,当时 time debug 定位到 redis get 操作耗时比较多(当时是 2 秒左右),但并没有在这方面做修复,后面通过减少了 swoole 的进程数解决了。
请求延迟监控图
每个小时的开始,请求会比较集中
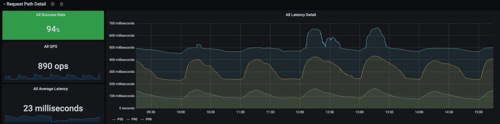
请求流程时间拆分图
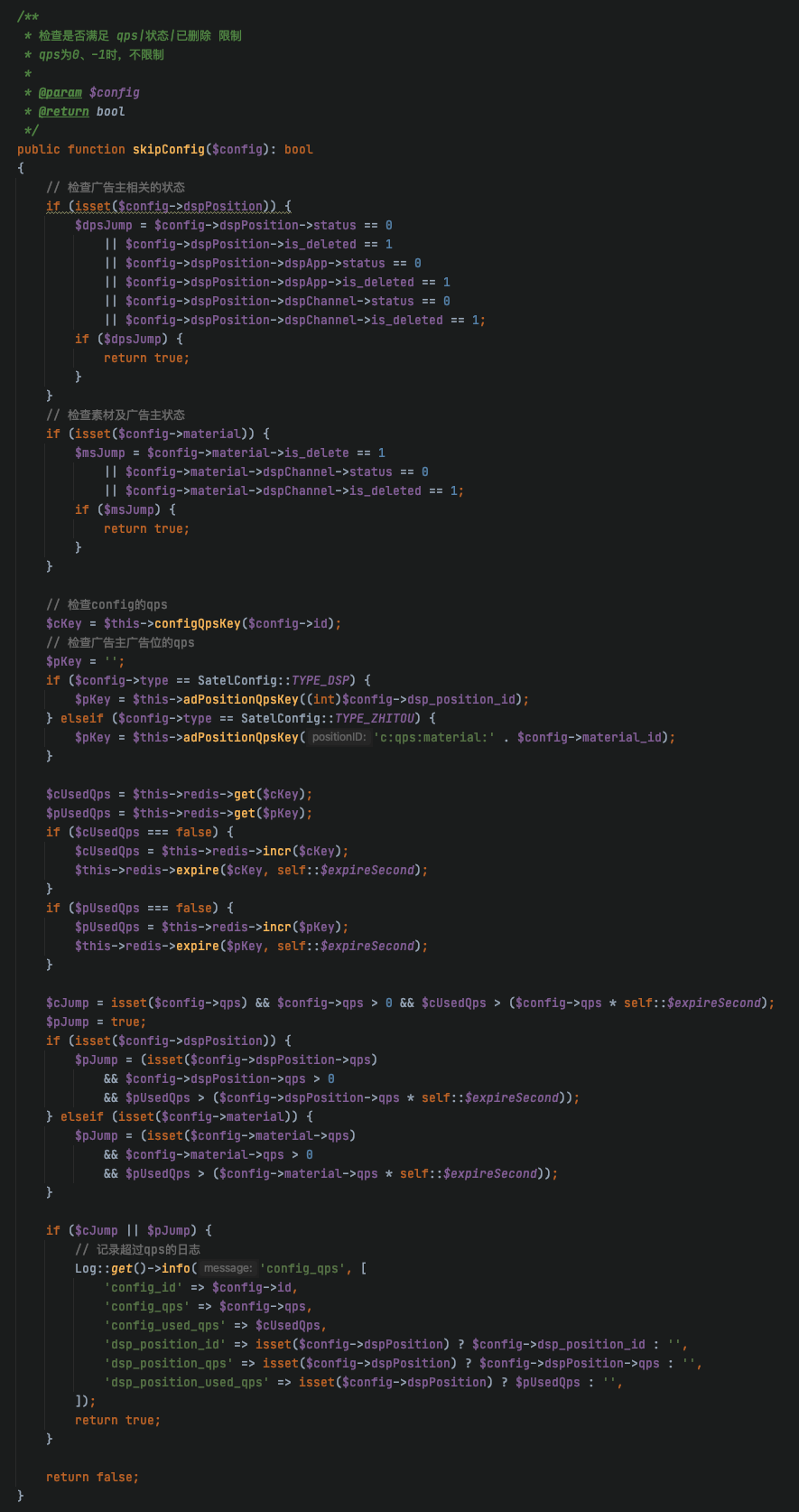
发现 qps 相关的代码段执行时间比较长,下面附上相关代码段

QPS 相关代码段

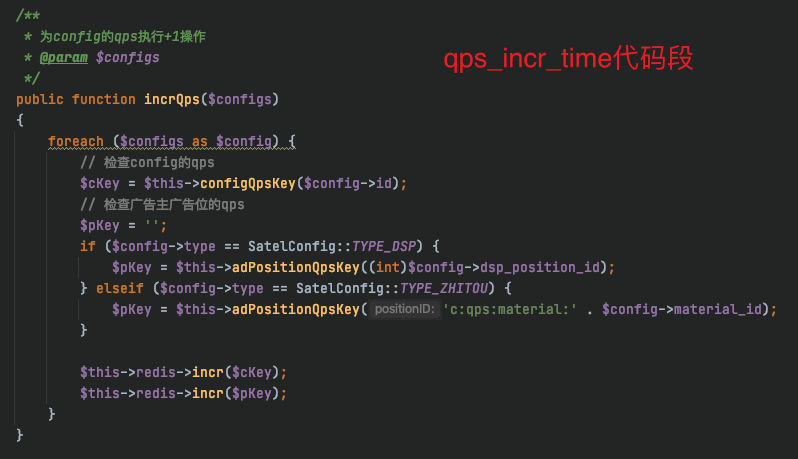
第 1 条附言 · 2020 年 12 月 30 日
大家可以关注一下qps_incr_time代码段,这个函数上半部分只是用于组装string key,下面进行redis incr操作,延迟较高的统计里,这部分耗时还是比较严重的;config的个数,一次请求里,1-10个不等。上半部分获取key,肯定不会耗时这么长,那么耗时的应该就是redis incr操作,查看了一下redis 慢日志
1) 1) (integer) 65757
2) (integer) 1609300166
3) (integer) 10291
4) 1) "INCR"
2) "c:qps:media-module:669527301130:1609297200"
2) 1) (integer) 65756
2) (integer) 1609291966
3) (integer) 10545
4) 1) "GET"
2) "c:qps:config:764:1609290000"
3) 1) (integer) 65755
2) (integer) 1609275925
3) (integer) 12119
4) 1) "SETEX"
2) "c:req_id:2618107d473d4a5da830e8c3c1fc9a8e"
3) "60"
4) "1"
确实有一些incr set get时间比较长,超过了10000微秒,但是图中qps_incr_time代码段执行时间是170毫秒,那么这么大的差距是哪里来的呢?
第 2 条附言 · 2020 年 12 月 31 日
感谢大家提出的建议和帮助,经过昨天排查,初步判断就是redis服务器的问题:
- 当初项目设计时,由于比较着急,并没有设计缓存服务器,redis服务器和其他项目是共用的
- 通过redis慢日志可以看出,一条命令执行耗时10ms,这已经很不正常了,正常来说应该在几百微秒
- 代码写的也有问题,循环调用redis,浪费了太多IO!!!1次请求,大概会执行4、50次redis操作,项目qps 1000出头时,redis的ops能达到3、40000。
初步优化方案:
- 首先优化代码,把循环操作redis的代码换成pipeline批量操作,可以大大减少IO
- 使用php yac 扩展,为redis再加一层缓存,减少redis服务器压力
- 更换云redis服务器,维护和扩展都比较方便
第 3 条附言 · 2021 年 1 月 9 日
更换了云Redis服务器,优化了redis操作语法,情况有所改善,但是不明显。
关键来了:
发现新建的一台API服务器,配置和负载和其他服务器一样,但cpu占用率要比之前的几台机器高;
经过排查,发现新机器tcp连接TIME_WAIT状态在8万个左右;其他的服务器都是在1万左右;原来以前的服务器都修改过tcp内核参数:
net.ipv4.tcp_keepalive_time=1200
net.ipv4.tcp_max_syn_backlog=8192
net.ipv4.tcp_max_tw_buckets=10000
把新主机也调整一下tcp内核参数之后,发现cpu使用率减少了,监控中响应延迟也下来了!!!
问:
但是为什么单机负载300多qps,TIME_WAIT确有8万多个呢?
答:
查看TCP链接状态之后,发现项目中连kafka时,没有用连接池,请求一次新建一次连接,浪费了大量服务器资源;
解决方案:
上面修改内核参数,只是治标不治本,后面打算把项目中的kafka用上连接池,然后把TCP内核参数再修改回去。
 |
1
mitu9527 2020 年 12 月 30 日 这么多台服务器,一般不能才 1000 多 qps 。
感觉你这问题不是很难的样子,看看硬件资源消耗,再多看看各种日志,应该就能找到问题所在。 |
 |
2
Jeyfang 2020 年 12 月 30 日
尝试下排除法咯,注释下各耗时严重的地方,然后单独去排查。期待这问题解决的后续
|
 |
3
imhui 2020 年 12 月 30 日
有项目用了 hyperf,关注一波
|
 |
4
imgbed 2020 年 12 月 30 日 via Android
mysql 数据量大吗?
|
 |
5
yuandj OP @imgbed mysql 数据量不大,是有缓存层的,缓存是永久有效,之前排查到 Redis get 操作耗时 2 秒,会不会是和缓存相关的问题呢,但当时在排查了 redis 慢日志,并没有耗时较久的命令
|
 |
6
wangbenjun5 2020 年 12 月 30 日
你们 QPS 居然用代码去统计,难道不能用 nginx 访问日志去统计么
|
|
7
yuandj OP @wangbenjun5 不是做统计,是用来做请求限制
|
 |
8
awanganddong 2020 年 12 月 30 日
这个是 adx 平台,还是 dsp 平台。
是不是 redis 缓存击穿了 |
 |
9
liuxu 2020 年 12 月 30 日
性能分析靠猜测三言两语说不清,最起码一个系统资源消耗和 xhprof 日志得给出来
|
 |
10
lbp0200 2020 年 12 月 30 日
QPS1000 多,也是大站了
|
 |
11
z5864703 2020 年 12 月 30 日
redis 的 qps 多少,有时并不是 redis 执行慢,而是 qps 高,本身单线程排队执行下来就延迟高了。
针对这种情况批量操作 redis 可以用管道和 lua 脚本,减少网络交互延迟 |
 |
12
nowgoo 2020 年 12 月 30 日
可能 redis 的网卡打满了?缓存的数据不宜太大
|
 |
13
wangritian 2020 年 12 月 30 日
你能做的事情还有很多,确认业务机器、redis 、mysql 的负载和带宽,单独编写接口做压力测试,尽可能多收集信息,再做思考
|
 |
14
keller 2020 年 12 月 30 日
QPS 统计改成异步吧
不要实时计算,异步计算好结果,下次请求的时候直接从缓存拿上次结算好的数据做限制 |
|
15
yuandj OP @z5864703 @wangritian 由于没运维,机器负载和带宽大概排查了一下,没大波动,初步怀疑就是 redis 这里有问题(上面更新了 redis 慢日志),后面试试减少 redis io,提高 redis 配置尝试一下
|
 |
16
GGGG430 2020 年 12 月 30 日
直接线上短时间 strace -T -tt -p 123 -o log 看看某个 swoole 的 worker 在干啥, 然后找找里面耗时高的系统调用在干啥, 精准定位问题
|
 |
17
HanMeiM 2020 年 12 月 30 日
mysql 和 redis 这种还是直接上云吧。。。如果真有问题,你们没运维也搞不定啊
|
 |
18
opengps 2020 年 12 月 30 日
1000 的 qps,一台数据库,关注下数据库这台机器的硬盘 io 是不是瓶颈
|

 |
20
chengfeng 2020 年 12 月 30 日 via iPhone
既然觉得是 redis 的问题,直接租个高配版 redis 切换过去看看效果呗
|
 |
21
ebingtel 2020 年 12 月 30 日
redis 用池化连接了么?
|
 |
22
liuhan907 2020 年 12 月 30 日 via Android
我建议你可以考虑接入 prometheus,细致的分析每个操作的耗时。能更加精确的定位瓶颈。
|
 |
23
zhuzhibin 2020 年 12 月 30 日 via iPhone
我就想问协程框架好不好用 上手如何?
|
 |
24
AlanLeung2018 2020 年 12 月 30 日
先排查是不是 mysql 慢查询造成的慢请求,然后再检查一下是不是某个时间段 fpm 进程数太多了
|
 |
25
iConnect 2020 年 12 月 30 日
这个情况大概率是 redis 的故障,先把 redis 服务器扩容或提高配置,或者干脆切到云服务商的专业 redis 云跑一段时间,对比一下,基本上就能诊断出来了。
|
 |
26
honkki 2020 年 12 月 30 日
redis 的配置是否有问题
|
 |
27
sagaxu 2020 年 12 月 31 日 via Android
1. 先确认 php 的 redis 用了连接池,池的大小,空闲多少
2. for 循环里每次两个 incr,10 个 config 的时候就是 20 个 incr,考虑做成批量更新 |
 |
28
dusu 2020 年 12 月 31 日 via iPhone
显然是 redis pool 到了最高并发量 导致 hyperf worker 协程都卡在了 redis 这头 而 redis 又查不出慢查询的原因
建议把 qps 部分或者高频又低重要性的 redis 操作都换成 asyncQueue 或者其他异步单线程任务试试看看协程能不能缓解。 |
 |
29
simple2025 2020 年 12 月 31 日 via Android
感觉是不是 redis get 的一些值字节太大?
|
 |
30
sadfQED2 2020 年 12 月 31 日 via Android
先确认一下硬件资源占用,每台机器的硬盘 io,网络 io,cpu,内存
先确定不是内存以后再定位是哪台机器。 另外,项目里面建议引入 opentarcing |
 |
32
surfire91 2020 年 12 月 31 日
@yuandj
"确实有一些 incr set get 时间比较长,超过了 10000 微秒,但是图中 qps_incr_time 代码段执行时间是 170 毫秒,那么这么大的差距是哪里来的呢?" qps_incr_time 代码段 里遍历了一个数组 configs,每个元素要执行两次 redis incr, 如果 configs 元素的数量多几个,执行 170ms 也正常。 另外 redis incr 需要 10ms 的话,肯定是不正常的。 |
 |
33
dedemao 2020 年 12 月 31 日
请教下“请求延迟监控图”和“请求流程时间拆分图”是如何获取的呢
|
 |
34
fuxkcsdn 2020 年 12 月 31 日
skipConfig 里的 $cUsedQps, $pUsedQps 这 2 个可以用 mget 来获取
incrQps 方法 可以通过 pipe 或者事务来执行,速度会提高很多 如果 incrQps 里那个循环量很大的话,那直接改这里性能就能有很大提升了 |
 |
35
jeristiano 2020 年 12 月 31 日
建议你去 hyperf 官方群去问问,他们经常为用户提供建议和反馈
qq 862099724 |
 |
37
mpanda 2020 年 12 月 31 日
第一直觉,反正不是 php 的锅
|
|
38
sagaxu 2020 年 12 月 31 日 via Android
咱们好像是同行,这个行业 qps 做到单机 1 万才算及格,rtb 响应时间(含网络)一般不宜超过 200ms 。不含 dmp 的纯 dsp,单机普遍能做到 10 万 qps 。
|