
这是一个创建于 1110 天前的主题,其中的信息可能已经有所发展或是发生改变。
如图
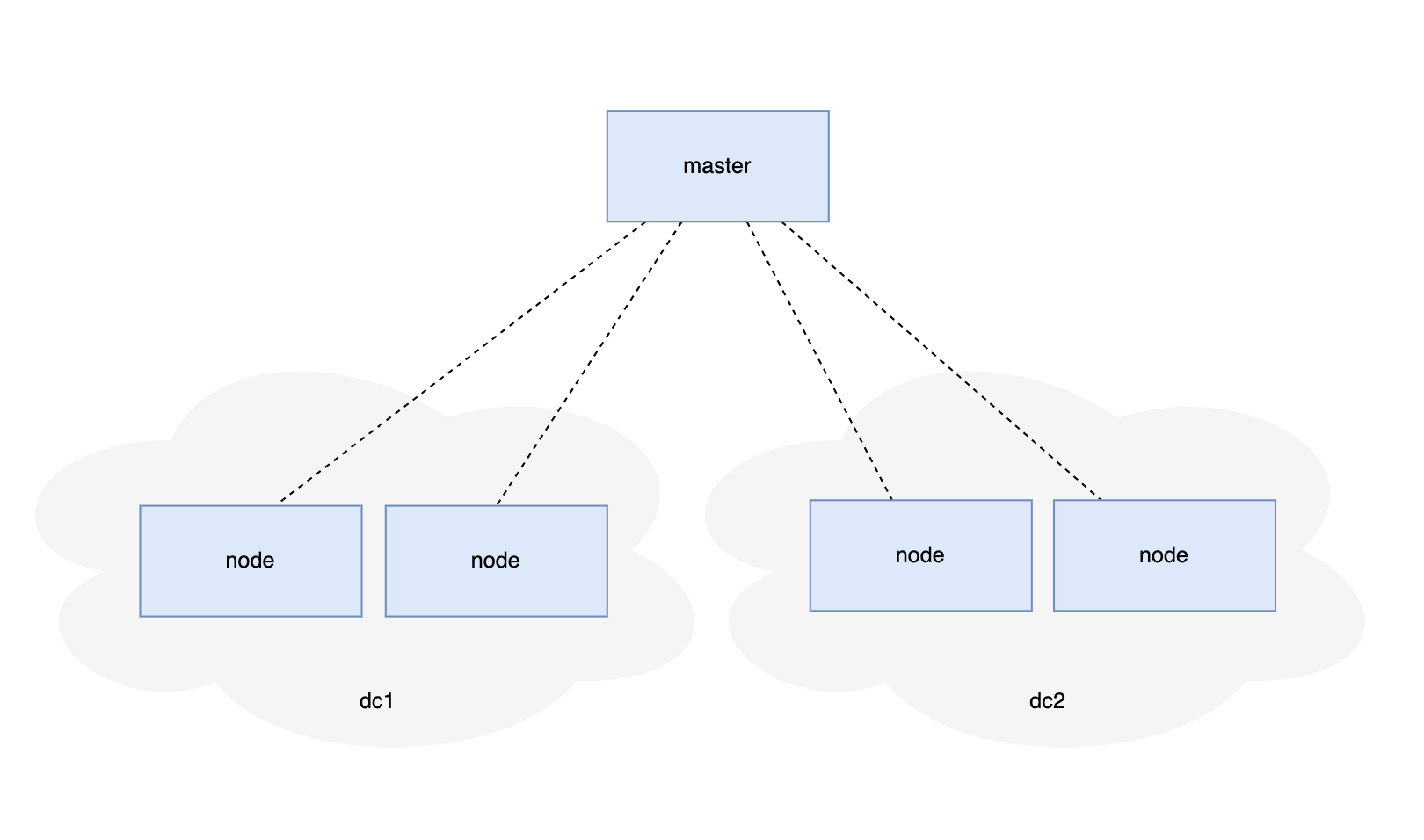
master 要 和 node 之间保持数据同步,数据可能「单向的」也可能是「双向」的。
业务场景数据量 < 100 万
最初的解决方案:
采用 MQ ,master 发布消息,各个 node 订阅消息,做到最终一致性。
如果是反向通信,就 node 发布,master 订阅。
场景:
1 、新加入 node 需要同步全量数据,再同步增量数据,达到最终一致性。
2 、node 可能离线一段时间,之后恢复在线,需要一段时间后达到最终一致性。
这个数据同步过程处理起来比较复杂。
so ,能否使用 etcd/consul 等,整个作为一个集群,用 kv 存储来代替最初的方案,满足上面的场景?
 |
1
Ehco1996 2021-12-22 16:05:47 +08:00
主要是看成本和数据的形式吧
成本说的是机器(网络 cpu 带宽) 还有数据是看 kv 这种简单接口够不够你业务上的需求 如果上述两点不满足,那就不可用 btw 小于 100w 的数据量为啥要上分布式呢?单纯是想有多份数据冗余么,如果是这样为啥不直接 mysql 主从呢 |
 |
2
BeijingBaby OP @Ehco1996 机器成本满足、kv 结构这 2 个满足。
对的,是为了满足跨区域可用性。 node 只有一个很小的功能,数据小,部署 mysql 成本感觉更高。 补充:dc1 和 dc2 网络不互通的,但都和 master 通。 |
|
3
Ehco1996 2021-12-22 16:32:03 +08:00
@BeijingBaby 网络不通的话 etcd 是部署不了的,而且 mysql 的成本明显比 etcd 低很多,有大把的主从同步工具可以用
|
|
4
BeijingBaby OP @Ehco1996 好的感谢,我再参考下。
|
 |
5
qingtengmuniao 2021-12-22 23:43:50 +08:00
提几个点,etcd 是使用 raft 实现高可用的一个简单 kv 。但是存储量级很小,单集群到 GB 级别,到 TB 可用性就不太高了,所一般用作元信息而非数据存储,而且 raft 要求集群内所有 peer 互通。你这个只有 master 跟其他人通是不太行的。
就你原来的架构,master 部署一个 kafka ,各个集群订阅 kafka 不挺好吗? |
|
6
BeijingBaby OP @qingtengmuniao 感谢回复,看来这种场景 raft 算法不合适,原来 MQ 方式跑了一段时间,主要就是新增 node 初次全量同步,以及同步耗时期间新增数据等处理麻烦。
|
 |
7
SmiteChow 2021-12-23 09:39:04 +08:00
etcd 本身就是分布式的,没问题。主要的问题 etcd 是用来做配置的,承载不了高并发的写操作,数据量也不能太大,有时效性的业务恐怕不符合。
|
|
8
BeijingBaby OP @SmiteChow 感谢回复,考虑 etcd/consul 确实是基于它们的分布式一致性特性,因为本身业务场景数据不多,但是访问压力很大(会存在很多 node ),新增 node 、卸载 node 等数据同步自己管理麻烦,想偷个懒。
|
 |
9
fengjianxinghun 2021-12-23 10:37:06 +08:00
tidb 啊
|
|
10
qingtengmuniao 2021-12-23 10:41:19 +08:00
@BeijingBaby
1. 可以自己写一个定期 truncate 然后做 snapshot 的逻辑呀,记下 truncate 点和 snapshot 的对应关系。每次有新节点加入先要 snapshot ,然后从对应 truncate 点往后拉取数据。 2. 同步期间新增数据,就追加到 Queue 不就好了? 最终一致性还是比较容易保证的。 |
 |
11
cloudzhou 2021-12-23 13:04:28 +08:00
不要通过 etcd/consul 交换数据本身,而是通过 etcd/consul 交互事件,然后事件触发数据的更新
简单例子,一个分布式 version ,然后数据 version 对象只能递增,最后通过 version 获取对象 |
|
12
BeijingBaby OP |