推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 1496 天前的主题,其中的信息可能已经有所发展或是发生改变。
有会 python 的 pandas 库的朋友么,为何第二种方法覆盖存储前面的表,而第一种则可以全表保存
全表保存:
 尾表保存(之前的表全覆盖了):
尾表保存(之前的表全覆盖了):
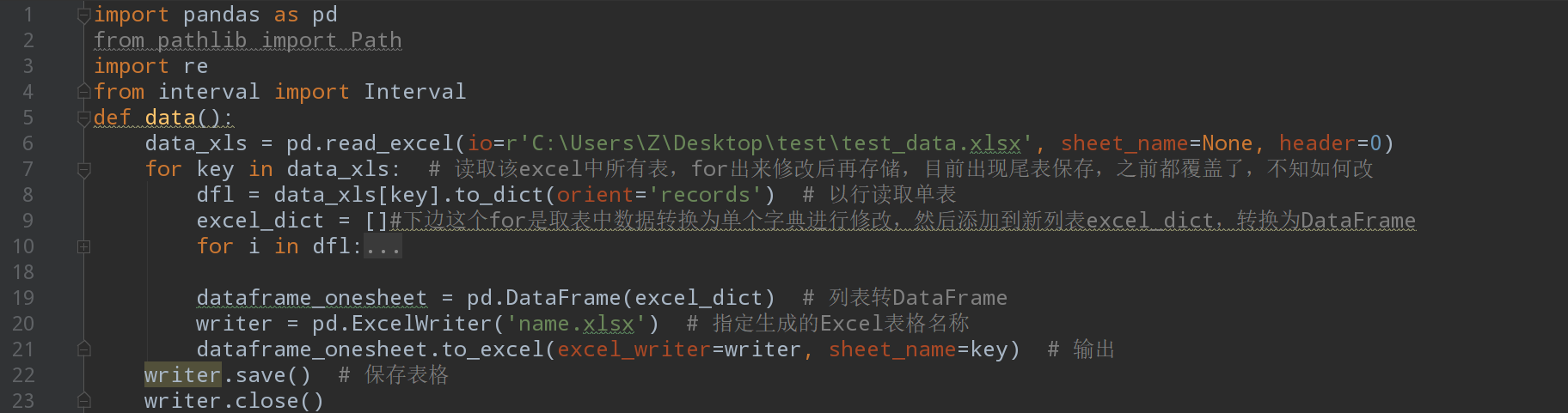
以下为部分代码,有朋友能指正下错误如何改正么,感谢
data_xls = pd.read_excel(io=r'C:\Users\Z\Desktop\test\test_data.xlsx', sheet_name=None, header=0)
for key in data_xls:
for i in dfl:
...
dfl = data_xls[key].to_dict(orient='records') # 以行读取单表
excel_dict = []
dataframe_onesheet = pd.DataFrame(excel_dict) # 列表转 DataFrame
writer = pd.ExcelWriter('name.xlsx') # 指定生成的 Excel 表格名称
dataframe_onesheet.to_excel(excel_writer=writer, sheet_name=key) # 输出
writer.save() # 保存表格
writer.close()
 |
1
user8341 2020-10-23 16:40:30 +08:00
这难道不是由于
writer = pd.ExcelWriter('name.xlsx') 这句话在循环外与在循环里的差别? |
 |
2
d0v0b OP @user8341 不是的,
for key in data_xls: #遍历各表, writer = pd.ExcelWriter('name.xlsx') #保存各表数据为 dataframe 给下一步转换为 excel, 按理来说这种循环覆盖我最先也是考虑你说的这种,我这边也尝试过改变循环位置,结果未变。 |
 |
3
qile1 2020-10-25 15:23:43 +08:00
https://github.com/pandas-dev/pandas/issues/3441
参考这个看看,感觉你把 excel 文件读取的字段都变为 key,这样保存时候多个列会生成好多个表 sheet 吧 |
 |
4
wyxls 2020-12-25 16:44:00 +08:00
for key in data_xls,这里好像默认只取了表格里最后一列的数据生成 dict,因为只有一列,所以不管内部 for i in df1 怎么处理都只有一列数据
另外你代码里写的 dfl,注释里写的 df1…… |