
这是一个创建于 319 天前的主题,其中的信息可能已经有所发展或是发生改变。
背景
随着业务的日趋复杂,做全量回归也越来越困难 为了更加精确的定位后台项目改动所造成的影响,回归范围划定精确,提升测试效率 需要对 Java 代码提交影响面进行分析
调研
除了少量相关英文文献,未从 Google 文献和 github 查找相关开源成熟的技术和方案。
文献:Chianti: A Tool for Change Impact Analysis of Java Programs
通过文献,结合个人开发经验,决定自主实现,主要面临的问题是 Java 文件解析和 diff 信息解析。
经过 Google 搜索找到了 python 相关的解析库,遂决定使用 python 开发此功能。
实现
大致原理同 Idea 的 Find Usage 一致,通过代码改动定位代码影响,并不断遍历受影响的类和方法直至找到最上层的 controller 层
代码主要由 python 编写,主要涉及 2 个库:
- javalang java 文件语法解析库
- unidiff git diff 信息解析库
通过 javalang 语法解析获取每个 Java 文件的 import class extends implements declarators methods 等信息,使用 sqlite3 存储 Java 文件解析结果,拆分成 project class import field methods 几个表,分别存储对应信息,然后通过 sql 查询方法调用
通过 unidiff 解析 git diff 信息( diff file, added_line_num, removed_lin_num)
然后根据文件增删的代码行去判断影响了哪些类和方法,不断遍历受影响的类和方法直至找到最上层的 controller 层
sqlite3 表结构
表结构如下
CREATE TABLE project (
project_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
project_name TEXT NOT NULL,
git_url TEXT NOT NULL,
branch TEXT NOT NULL,
commit_or_branch_new TEXT NOT NULL,
commit_or_branch_old TEXT,
create_at TIMESTAMP NOT NULL DEFAULT (datetime('now','localtime'))
);
CREATE TABLE class (
class_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
filepath TEXT,
access_modifier TEXT,
class_type TEXT NOT NULL,
class_name TEXT NOT NULL,
package_name TEXT NOT NULL,
extends_class TEXT,
project_id INTEGER NOT NULL,
implements TEXT,
annotations TEXT,
documentation TEXT,
is_controller REAL,
controller_base_url TEXT,
commit_or_branch TEXT,
create_at TIMESTAMP NOT NULL DEFAULT (datetime('now','localtime'))
);
CREATE TABLE import (
import_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
class_id INTEGER NOT NULL,
project_id INTEGER NOT NULL,
start_line INTEGER,
end_line INTEGER,
import_path TEXT,
is_static REAL,
is_wildcard REAL,
create_at TIMESTAMP NOT NULL DEFAULT (datetime('now','localtime'))
);
CREATE TABLE field (
field_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
class_id INTEGER,
project_id INTEGER NOT NULL,
annotations TEXT,
access_modifier TEXT,
field_type TEXT,
field_name TEXT,
is_static REAL,
start_line INTEGER,
end_line INTEGER,
documentation TEXT,
create_at TIMESTAMP NOT NULL DEFAULT (datetime('now','localtime'))
);
CREATE TABLE methods (
method_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
class_id INTEGER NOT NULL,
project_id INTEGER NOT NULL,
annotations TEXT,
access_modifier TEXT,
return_type TEXT,
method_name TEXT NOT NULL,
parameters TEXT,
body TEXT,
method_invocation_map TEXT,
is_static REAL,
is_abstract REAL,
is_api REAL,
api_path TEXT,
start_line INTEGER NOT NULL,
end_line INTEGER NOT NULL,
documentation TEXT,
create_at TIMESTAMP NOT NULL DEFAULT (datetime('now','localtime'))
);
主要介绍 methods 表 method_invocation_map 字段,存储解析方法用到的类和方法,便于后续查询哪些方法用到了某类或方法。 method_invocation_map 字段存储示例:
{
"com.XXX.Account": {
"entity": {
"return_type": true
}
},
"com.XXXX.AccountService": {
"methods": {
"functionAA(Map<String#Object>)": [303]
},
"fields": {
"fieldBB": [132]
}
}
}
分析调用
这部分主逻辑改成分析改动的类或方法被哪些方法调用,通过 sql 的方式查询结果,示例代码:
SELECT
*
FROM
methods
WHERE
project_id = 1
AND (json_extract(method_invocation_map,
'$."com.xxxx.ProductUtil".methods."convertProductMap(QueryForCartResponseDTO)"') IS NOT NULL
OR json_extract(method_invocation_map,
'$."com.xxxx.ProductUtil".methods."convertProductMap(null)"') IS NOT NULL)
展示方式
之前展示方式由树图和关系图展示,但是树图展示链路不清晰,关系图节点坐标不合理,这部分也进行了优化,根据节点关系计算节点坐标,关系链路越长,横坐标越大,展示更清晰,示例代码:
def max_relationship_length(relationships):
if not relationships:
return {}
# 构建邻接列表
graph = {}
for relationship in relationships:
source = relationship['source']
target = relationship['target']
if source not in graph:
graph[source] = []
if target not in graph:
graph[target] = []
graph[source].append(target)
# BFS 遍历计算每个节点到起点的最长路径长度
longest_paths = {node: 0 for node in graph.keys()}
graph_keys = [node for node in graph.keys()]
longest_paths[graph_keys[0]] = 0
queue = deque([(graph_keys[0], 0)])
while queue:
node, path_length = queue.popleft()
if not graph.get(node) and not queue and graph_keys.index(node) + 1 < len(graph_keys):
next_node = graph_keys[graph_keys.index(node) + 1]
next_node_path_length = longest_paths[next_node]
queue.append((next_node, next_node_path_length))
continue
for neighbor in graph.get(node, []):
if path_length + 1 > longest_paths[neighbor]:
longest_paths[neighbor] = path_length + 1
queue.append((neighbor, path_length + 1))
return longest_paths
展示效果
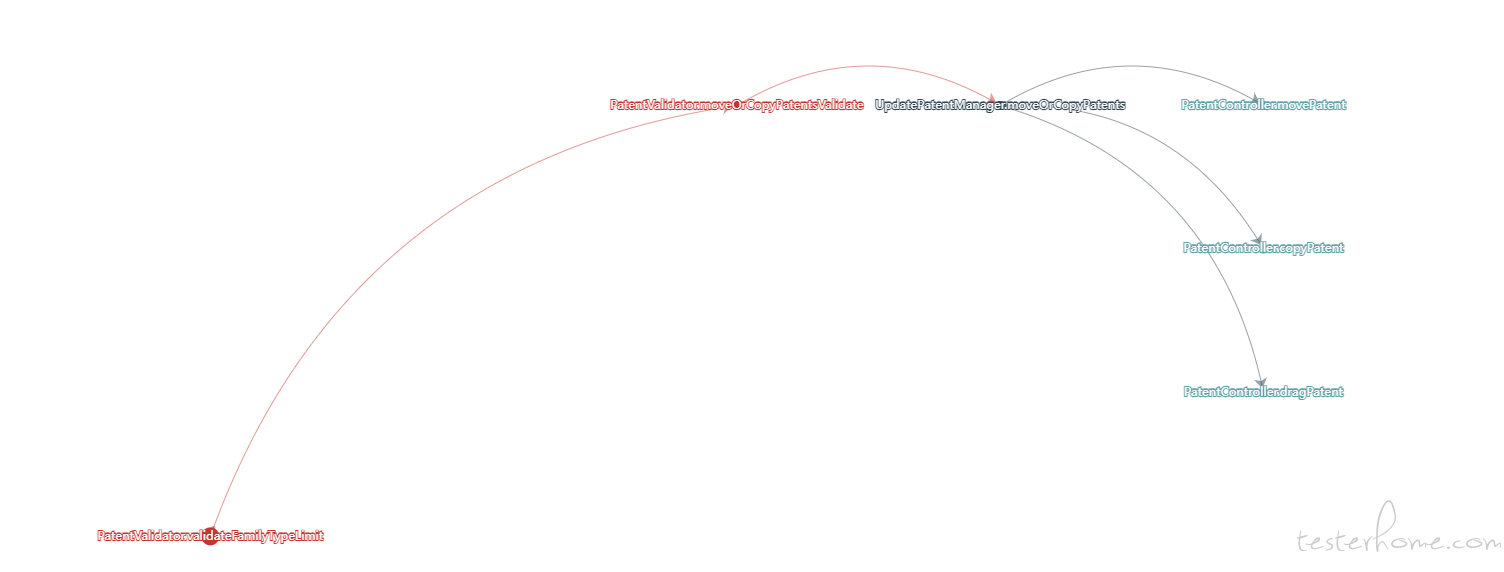
3 种分析方式
JCCI 可以分析同一分支两次提交、分析指定类、分析两个分支的功能,示例:
from path.to.jcci.src.jcci.analyze import JCCI
# 同一分支不同 commit 比较
commit_analyze = JCCI('git@xxxx.git', 'username1')
commit_analyze.analyze_two_commit('master','commit_id1','commit_id2')
# 分析一个类的方法影响, analyze_class_method 方法最后参数为方法所在行数,不同方法行数用逗号分割,不填则分析完整类影响
class_analyze = JCCI('git@xxxx.git', 'username1')
class_analyze.analyze_class_method('master','commit_id1', 'package\src\main\java\ClassA.java', '20,81')
# 不同分支比较
branch_analyze = JCCI('git@xxxx.git', 'username1')
branch_analyze.analyze_two_branch('branch_new','branch_old')
灵活配置
可以在 config 文件配置 sqlite3 db 存储路径、项目代码存储路径和忽略解析的文件等,示例:
db_path = os.path.dirname(os.path.abspath(__file__))
project_path = os.path.dirname(os.path.abspath(__file__))
ignore_file = ['*/pom.xml', '*/test/*', '*.sh', '*.md', '*/checkstyle.xml', '*.yml', '.git/*']
结语
项目地址:JCCI, 欢迎大家试用并反馈,期待大家的 star~ 联系方式等都在 GitHub 项目的 readme 中,谢谢~~
 |
1
issakchill 319 天前
star 了 如果可以 可以弄成 docker 吗
 |
 |
2
Manley 319 天前 via Android
Op 强啊,之前开发的时候就考虑过这种东西,通过分析代码找出影响范围,做好测试。不过没找到现成的。支持一下!
|
 |
3
superychen 319 天前
已 star ,明天试试
|
 |
4
phrack 319 天前 via iPhone
codeql ,joern 之类现成的工具应该就行,不过造轮子确实好玩
|
 |
5
yanchao7511461 319 天前
666
|
 |
6
diiww OP @issakchill 好,后面整个 docker
|
|
8
diiww OP @superychen 嗯 有问题可以直接反馈我
|
 |
9
24Arise 318 天前
这东西做好了,意义重大啊 ~
|
|
11
Manley 318 天前
昨晚上回去想了想,这东西如果扩展一下对接上自动化测试,楼主功德无量
|
 |
14
luozic 318 天前
这个不错,实际可以找个比较大的开源 Java 项目,跑一下 commit 实验一下数据
|
 |
16
teddybun 315 天前
简单看了下,是单一项目的吧。类似 dubbo 等 RPC 框架的项目怎么分析?
|